Det foregår to stk kappløp for tiden. Det første kappløpet handler om AI-teknologien, der aktører som OpenAI (ChatGPT), Google (Gemini), Anthropic (Claude), xAI (Grok) og Perplexity kjemper om å utvikle de kraftigste og raskeste modellene. Hver dag lanseres nye AI-produkter og -tjenester som gjør avansert teknologi tilgjengelig for alle, ikke bare de med teknisk bakgrunn.
Det andre kappløpet handler om søk – hvordan vi finner informasjon. Utviklingen har gått fra enkle søkemotorer med tekstkommandoer til et fragmentert landskap hvor vi bruker Google, Bing, YouTube, TikTok, Instagram og nå i økende grad, direkte AI-plattformer. Brukere henter informasjon, inspirasjon og utfører handlinger som kjøp på tvers av mange kanaler. Det er avgjørende at vi skiller mellom disse to løpene, men adresserer begge. Mens tradisjonell SEO har fokusert på å rangere i en liste med blå lenker, tvinger AI oss til å tenke nytt. Velkommen til en ny æra av optimalisering.
Fra SEO til AI SEO / AEO / GEO / LLMO: De nye begrepene du må kjenne
I takt med at AI-assistentene blir en integrert del av søk, har det dukket opp nye fagbegreper. Selv om de overlapper, har de litt ulikt fokus:
- AEO (Answer Engine Optimization): Fokuserer på å optimalisere innhold for å gi direkte, konsise svar på brukernes spørsmål. Målet er å bli det foretrukne svaret som AI-en velger å presentere, enten det er i en tekstboks, et stemmesvar fra en assistent eller i Googles «AI Overviews».
- GEO (Generative Engine Optimization): En strategi for å optimalisere innhold slik at det blir funnet, forstått og brukt av generative AI-modeller som ChatGPT, Gemini og Perplexity. Målet er å sikre at merkevaren din blir synlig og nevnt i de AI-genererte svarene når brukere søker etter løsninger, produkter eller ekspertise du tilbyr.
- LLMO (Large Language Model Optimization): Handler om å gjøre innholdet ditt lett tilgjengelig og forståelig for de store språkmodellene som driver AI-tjenestene. I motsetning til tradisjonell SEO, som fokuserer på søkeord, handler LLMO om å bli en autoritativ kilde som AI-en stoler på og siterer.
Selv om navnene er forskjellige, er målet det samme: Sørg for at ditt innhold blir valgt som kilde av AI-en. Gartner spår at trafikken fra tradisjonelt organisk søk vil falle med 25 % innen 2026, ettersom brukerne i økende grad får svarene sine direkte fra AI.
Fra 10 blå lenker til ett enkelt svar: Hva er egentlig forskjellen?
Kjernemekanismen i AI-optimalisering ligner på tradisjonell SEO. I begge tilfeller er det «boter» (crawlere) som henter, indekserer og vurderer innholdet ditt basert på en rekke signaler. Fundamentet er det samme: å gjøre informasjonen din tilgjengelig og forståelig for en maskin. Den revolusjonerende forskjellen ligger ikke i hvordan informasjonen samles inn, men i hvordan den presenteres for brukeren.
- Tradisjonell SEO: Målet var å klatre på en rangert liste med 10 blå lenker. Selv om du ikke var nummer én, hadde du fortsatt en god sjanse til å få klikk som nummer to, tre eller fire. Det var flere «vinnere» på hver søkeside.
- AI SEO (AEO/GEO/LLMO): Målet er å bli kilden til det ene, sammenfattede svaret som AI-en genererer. AI-en fungerer som en kurator som leser flere kilder, syntetiserer informasjonen og presenterer ett enkelt, autoritativt svar, ofte med langt færre lenker.
Tenk at før var det du som hadde AI sin rolle i å vurdere lenkene, titlene, meta beskrivelsene. Nå er det AI som «klikker og vurderer» disse lenkene, før den sammenfatter en anbefaling eller svar til deg. Konsekvensen er brutal: Søkeresultatet går fra å være en liste med mange valgmuligheter til å bli en «vinneren-tar-alt»-arena. Hvis innholdet ditt ikke blir valgt som grunnlag for AI-svaret, blir du i praksis usynlig for den brukeren, i det søket. Dette skiftet tvinger oss til å heve standarden fra å være «god nok til å rangere» til å være «den beste og mest troverdige kilden» om et emne.
Hvordan «tenker» en AI? En forenklet forklaring
For å optimalisere for AI, hjelper det å forstå hvordan den behandler informasjon. En stor språkmodell (LLM) som ChatGPT er ikke et orakel med bevissthet; den er en ekstremt avansert mønstergjenkjenner og sannsynlighetsberegner. Tenk på det slik:
- Trening – Den lærer språkets «musikk»: Modellen blir trent på enorme mengder tekst og kode fra internett. Gjennom denne prosessen bygger den et komplekst nevralt nettverk. Dette nettverket lærer ikke «fakta» slik vi gjør, men heller de statistiske sammenhengene mellom ord, setninger og konsepter. Den lærer hvilke ord som sannsynligvis følger etter hverandre i en gitt kontekst.
- Behandling – Den bygger en «meningsvektor»: Når AI-en leser innholdet ditt, konverterer den teksten til en matematisk representasjon – en såkalt «vektor». Denne vektoren fanger den semantiske meningen og konteksten. Godt strukturert innhold med klare overskrifter og tydelig språk skaper en renere og mer presis meningsvektor, noe som gjør det lettere for AI-en å forstå nøyaktig hva teksten din handler om.
- Anbefaling – Den søker etter «troverdige mønstre»: Når en bruker stiller et spørsmål, ser AI-en etter kilder hvis meningsvektorer matcher spørsmålet best. Her kommer E-E-A-T inn som en avgjørende faktor. AI-en har lært fra treningsdataene sine at informasjon som er knyttet til anerkjente forfattere, siteres ofte av andre troverdige kilder, og som finnes på veletablerte nettsteder, er statistisk sett mer pålitelig.
Den «anbefaler» derfor innhold som:
- Matcher spørsmålet tematisk: Svarer direkte og tydelig.
- Viser tegn på troverdighet: Har sterke E-E-A-T-signaler (forfatterinfo, kilder, lenker fra andre).
- Er lett å forstå og dekonstruere: Har god struktur (overskrifter, lister, schema).
AI-en «tenker» altså ikke, den kalkulerer sannsynlighet basert på mønstre. Din jobb er å skape innhold som er et så tydelig, troverdig og velstrukturert mønster som mulig.
Hvordan optimalisere for AI-søk? En praktisk guide
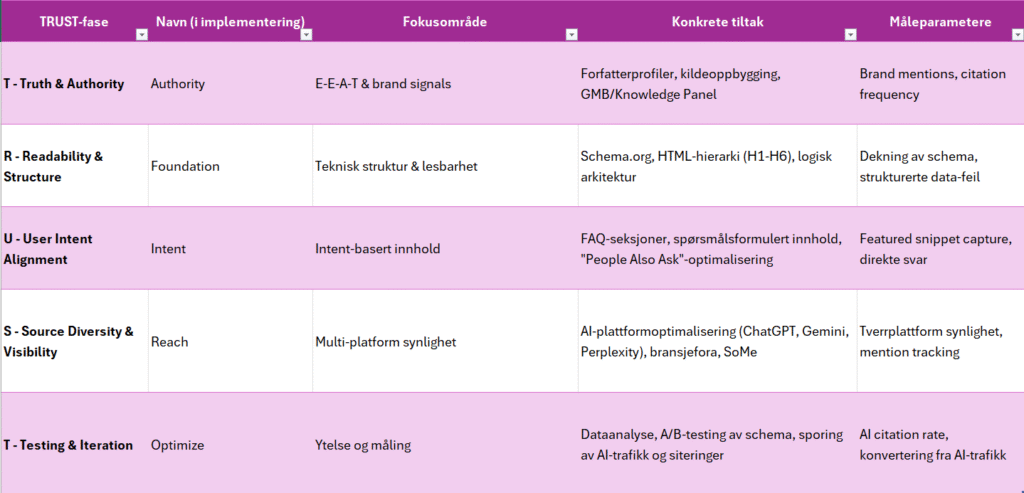
Ditt menneskelige fortrinn: Ekte erfaring kan ikke automatiseres
Her ligger den viktigste innsikten for alle som lager innhold: Den første E-en i E-E-A-T – Erfaring – er din fremste beskyttelse mot å bli irrelevant. En AI kan sammenfatte all eksisterende kunnskap på internett, men den kan ikke ha en genuin, personlig opplevelse. En språkmodell kan ikke:
- Faktisk teste et produkt og beskrive følelsen av kvaliteten.
- Besøke en restaurant og formidle stemningen.
- Gjøre seg personlige refleksjoner og tanker basert på mange års arbeid i en bransje.
Dette er ditt unike bidrag. Innhold som demonstrerer ekte, førstehånds erfaring – dine tanker, dine bilder, dine analyser – sender et kraftig signal til AI-motorene om at dette er originalt og verdifullt innhold. Det er vanskelig å kopiere og umulig for en AI å produsere på dine vegne.
Vanlige fallgruver du må unngå
I kappløpet om å tilpasse seg, er det lett å trå feil. Her er de vanligste fallgruvene:
- Overdreven bruk av AI til innholdsproduksjon: Å la en AI skrive hele artikler er den raskeste veien til generisk innhold som mangler personlig erfaring (E-E-A-T). Resultatet blir en tekst som ligner på alt annet der ute, og som AI-en ikke har noen grunn til å sitere. Bruk AI som en assistent for research og struktur, ikke som forfatter.
- Glemme strukturert data (Schema): Å tro at godt innhold alene er nok. Uten strukturert data gjør du det unødvendig vanskelig for AI-en å forstå konteksten i innholdet ditt raskt og korrekt. Dette er en av de viktigste tekniske faktorene.
- Fokusere kun på Google: Brukere stiller nå spørsmål direkte i ChatGPT, Perplexity, Claude og andre tjenester. Sjekk hvordan din merkevare og ditt innhold presenteres på disse plattformene også. Din synlighet er ikke lenger begrenset til én søkemotor. I tillegg er sosiale medier nå mer inkludert i Google Søk også, slik at din tilstedeværelse og engasjement i sosiale medier, også blir vurdert. Hvis brukerne kan finne flere kilder på at du og din bedrift er beste valg, så vil det bidra sterkt til å bli valgt av AI også.
- Ignorere «om oss» og forfattersider: Anonymt innhold skaper mistillit. Tydelige forfatterprofiler som viser ekspertise og en solid «om oss»-side er lavthengende frukt for å bygge troverdighet (Trustworthiness).
Verktøy og tankesett for den nye hverdagen
For å lykkes med AI SEO må du også justere arbeidsflyten din.
- Bruk AI til research, ikke til skriving: Bruk verktøy som ChatGPT eller Perplexity til å identifisere vanlige spørsmål, finne relaterte temaer og strukturere artiklene dine. Unngå å la AI skrive hele teksten, da dette ofte mangler den personlige erfaringen (E-E-A-T) som kreves.
- Test dine egne søk: Gå til ChatGPT, Perplexity og Google (med AI Overviews) og still spørsmål du ønsker å rangere for. Hvem siteres i dag? Hva slags svar gis? Dette er din nye konkurrentanalyse.
- Fokuser på «informational gain»: Ikke bare gjenta det alle andre sier. Hvilken unik innsikt, data eller erfaring kan du tilføre samtalen? Det er dette som gjør innholdet ditt verdig å bli sitert av en AI.
AI-boter: Ikke steng dem ute – slik tilrettelegger du riktig
En avgjørende, men ofte oversett faktor i AI-optimalisering er hvordan du håndterer AI-botene på nettstedet ditt. Mange nettstedeiere gjør feilen av å blokkere alle boter uten å forstå forskjellen mellom ulike typer AI-crawlere og deres formål.
Hvorfor du MÅ tillate AI-boter
I motsetning til tradisjonell SEO hvor du kunne rangere uten å bekymre deg så mye om boter, er AI-optimalisering helt avhengig av at AI-botene faktisk kan komme inn på nettstedet ditt. Hvis AI-crawlere blir blokkert i stor skala uten nyansering, kan du gå glipp av forbrukere som søker etter produktene eller tjenestene dine på ikke-Google-plattformer.
Tre grunner til at du må være selektiv med blokkering:
- Real-time henting: Når brukere stiller spørsmål i ChatGPT, kjører ChatGPTs ChatGPT-User bot faktisk nettsøk og laster ned søkeresultatsider i sanntid for å skaffe oppdatert informasjon til brukeren. Hvis denne boten er blokkert, vil ikke innholdet ditt bli funnet.
- Oppdatert informasjon reflekteres umiddelbart: I motsetning til tradisjonelt nettsøk, når du oppdaterer en side som blir hentet og sitert av ChatGPT eller Perplexity, reflekteres det oppdaterte innholdet i AI-ens svar i sanntid.
- Fremtidssikring: AI-søk vokser raskt, og brukere som til slutt klikker seg videre til nettstedet ditt fra AI-svar er bedre kvalifiserte og mer sannsynlig å konvertere.
Forskjellen mellom AI-bot-typer
Det finnes tre hovedkategorier av AI-boter, og det er viktig å forstå forskjellen:
1. Treningsdata-crawlere
Formål: Samler data fra nettsteder for å trene store språkmodeller (LLM-er) og hjelpe dem med å generere mer nøyaktige, menneskelignende responser.
- Crawler innhold periodisk for å bygge treningsdatasett
- Påvirker hvilke kilder AI-en «husker» og kan referere til
- Eksempler: GPTBot, anthropic-ai, Google-Extended
2. Sanntids-hentingsbotere
Formål: Noen AI-plattformer bruker også crawlere for å supplere sine førre-trente modeller med sanntidsdata, en prosess som kalles live retrieval.
- Trigges av spesifikke brukerspørsmål
- Henter fersk informasjon fra nettsteder
- Eksempler: ChatGPT-User, Perplexity-User
3. Søkeindeks-byggere
Formål: Noen bygger aktivt sine egne søkeindekser – rivaliserende databaser til Google og Bing – som til slutt kan informere innholdet de bruker i generative responser.
- Bygger egne søkeindekser uavhengig av Google/Bing
- Eksempler: OAI-SearchBot, PerplexityBot
Oversikt over viktige AI-boter
| Bot/Crawler | Selskap | Formål | User-Agent | Anbefaling |
|---|---|---|---|---|
| GPTBot | OpenAI | Treningsdata for GPT-modeller | GPTBot/1.1 |
Tillat for merkevaresynlighet |
| ChatGPT-User | OpenAI | Sanntidshenting for ChatGPT-brukere | ChatGPT-User/1.0 |
KRITISK å tillate |
| OAI-SearchBot | OpenAI | Søkeindeksering for ChatGPT Search | OAI-SearchBot/1.0 |
Tillat for fremtidig synlighet |
| ClaudeBot | Anthropic | Treningsdata for Claude | ClaudeBot |
Tillat for merkevaresynlighet |
| anthropic-ai | Anthropic | Bulk treningsdata | anthropic-ai |
Valgfri |
| PerplexityBot | Perplexity | Søkeindeksering | PerplexityBot |
Tillat for søkesynlighet |
| Perplexity-User | Perplexity | Brukerutløste forespørsler | Perplexity-User |
KRITISK å tillate |
| Google-Extended | Treningsdata for Gemini | Google-Extended |
Tillat for Gemini-synlighet | |
| Bingbot | Microsoft | Indeksering (brukt av Copilot) | bingbot |
KRITISK å tillate |
| Bytespider | ByteDance/TikTok | Treningsdata for Doubao | Bytespider |
Vurder å blokkere* |
| CCBot | Common Crawl | Åpen treningsdata | CCBot |
Vurder å blokkere* |
Praktisk robots.txt-oppsett
Her er en anbefalt robots.txt-konfigurasjon som balanserer synlighet med kontroll:
# ——— OPENAI ———
# Tillat søk og sanntidshenting (KRITISK)
User-agent: OAI-SearchBot
User-agent: ChatGPT-User
User-agent: ChatGPT-User/2.0
Allow: /
# Tillat treningsdata med begrensninger
User-agent: GPTBot
Disallow: /private/
Disallow: /admin/
Allow: /
# ——— ANTHROPIC (Claude) ———
User-agent: ClaudeBot
User-agent: anthropic-ai
Allow: /
# ——— PERPLEXITY ———
User-agent: PerplexityBot
User-agent: Perplexity-User
Allow: /
# ——— GOOGLE (Gemini) ———
User-agent: Google-Extended
Allow: /
# ——— MICROSOFT (Bing / Copilot) ———
User-agent: Bingbot
Allow: /
# ——— BLOKKER PROBLEMATISKE ———
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
Den nye standarden: llms.txt
Utover robots.txt har det dukket opp en ny, komplementær standard kalt llms.txt som fungerer fundamentalt annerledes enn tradisjonell robots.txt.
Hva er llms.txt?
llms.txt er ikke en robots.txt-erstatning eller -utvidelse. Den blokkerer ikke crawlere, dikterer ikke indekseringsatferd eller begrenser tilgang til innhold. I stedet fungerer den mer som en meny – et kuratert kart som leder AI-modeller rett til det mest verdifulle innholdet uten å måtte grave gjennom hele nettstedet.
Nøkkelforskjeller fra robots.txt:
| Aspekt | robots.txt | llms.txt |
|---|---|---|
| Formål | Adgangskontroll – forteller crawlere hva de IKKE kan besøke | Innholdskuratering – guider AI til det BESTE innholdet |
| Format | Enkle tekstdirektiver | Strukturert Markdown-dokument |
| Funksjon | Blokkerer/tillater tilgang | Fungerer som «skattekart» for AI |
| Timing | Prevents crawling | Optimizes inference |
Hvordan fungerer llms.txt?
llms.txt løser AI-relaterte utfordringer. Den hjelper med å overvinne kontekstvindubegrensninger, fjerner ikke-essensiell markup og skript, og presenterer innhold i en struktur optimalisert for AI-behandling.
Eksempel på llms.txt-innhold:
# Bedrift.no: AI-ressurser og tjenester
> En kuratert liste over høyverdige, LLM-vennlige ressurser designet for AI-systemer.
## Om oss
Vi er Norges ledende eksperter på digital markedsføring…
## Våre tjenester
– SEO og AI-optimalisering: /tjenester/seo-ai-optimalisering
– Innholdsmarkedsføring: /tjenester/innholdsmarkedsfoering
– Teknisk SEO: /tjenester/teknisk-seo
## Ressurser og guider
– Complete guide til AI SEO: /guide/ai-seo-komplett-guide
– E-E-A-T optimalisering: /guide/eeat-optimalisering
Status og implementering
Per nå er llms.txt ikke en industristandard. Store modeller som OpenAIs GPTBot og Anthropics Claude refererer fortsatt til robots.txt, ikke llms.txt. Det kan endre seg i fremtiden. Men for nå er det beste alternativet å holde robots.txt-filen tett justert.
Fremtiden er her
Overgangen fra tradisjonell SEO til AI-optimalisering er ikke noe som vil skje i fremtiden – det skjer nå. Bedrifter som tilpasser seg tidlig og fokuserer på å skape verdifullt, velstrukturert og troverdig innhold, vil ha et betydelig konkurransefortrinn i kampen om å bli AI-ens foretrukne kilde. I disse dager gjør jeg denne optimaliseringsjobben for flere kunder av meg, basert på en erfaringsbasert modell som gir gode resultater for AI søk.
Kilder:
{kind=link}
{kind=link}